SIMD in WebAssembly →
11th Feb, 2020WebAssembly SIMD (Single Instruction, Multiple Data) currently in development and soon will be added.
What is SIMD
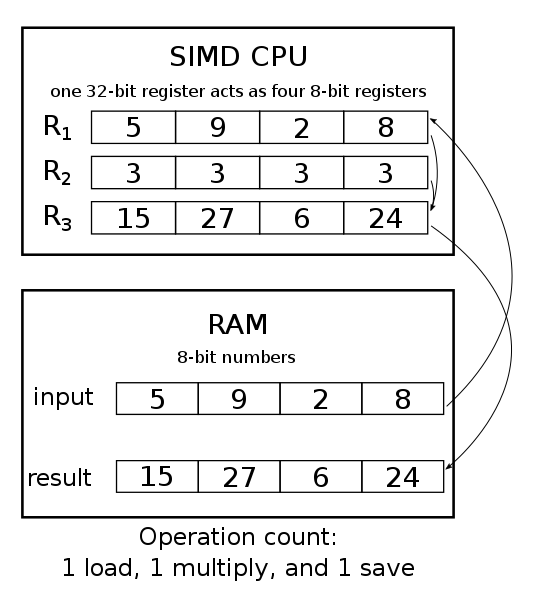
SIMD is an interesting concept of parallel computing and can make huge performance gains in some cases. What essentially SIMD is instead of performing a single calculation on a single element of an array or vector on single instruction it can perform calculations on multiple or all elements (depending on type and size) in a single SIMD instruction.
Areas which will have major performance gains
- Audio Processing
- Video, Image Processing
- Anything involving vector/tensor operations
It is commonly required in image processing to apply the same operation/calculation to all the pixels. Example might include changing hue of an image where it is needed to go through all the pixels and manipulate their rgb value.
Without SIMD

(Source: SIMD Wikipedia article)
With SIMD
(Source: SIMD Wikipedia article)
Similarly in machine learning and artificial intelligence vector & tensor product are needed to be calculated and SIMD can really fasten it up and improve performance by large factor.
Using SIMD with emscripten
SIMD can be enabled using -msimd128 flag when compiling using emscripten.
emcc -O3 -msimd128 in.c -o out.wasm
C function of example in above image:
void tripleArr(int *arr, int n) {
for (int i=0; i<n; i++) {
arr[i] *= 3;
}
}
Compiled without SIMD
(func $1 (; 1 ;) (param $0 i32) (param $1 i32)
(local $2 i32)
(local $3 i32)
(if
(i32.gt_s
(local.get $1)
(i32.const 0)
)
(loop $label$2
(i32.store
(local.tee $3
(i32.add
(local.get $0)
(i32.shl
(local.get $2)
(i32.const 2)
)
)
)
(i32.mul
(i32.load
(local.get $3)
)
(i32.const 3)
)
)
(br_if $label$2
(i32.ne
(local.tee $2
(i32.add
(local.get $2)
(i32.const 1)
)
)
(local.get $1)
)
)
)
)
)
)
Compiled with SIMD
(loop $label$3
(v128.store align=4
(local.tee $4
(i32.add
(local.get $0)
(i32.shl
(local.get $3)
(i32.const 2)
)
)
)
(i32x4.mul
(v128.load align=4
(local.get $4)
)
(i32x4.splat
(i32.const 3)
)
)
)
Wat in SIMD is omitted to show only main part i.e v128 align=4 instructions
WASM binary disassembled using Binaryen.